Dear BRIDE/ROCK experts,
after a stormy discussion about some ideas related to model-driven tools for
RTT I made an attempt to glue ROCK with BRIDE using Xtext framework for textual
DSL development. The results are still in pre-alpha stage (yet) and not ready
to download, but I think that some issues have been already identified. I
wanted to share my preliminary experience report with the community, as I hope
some of you may find it interesting.
As a remainder - the long-term goal is to have a full-featured Eclipse-based
environment for design and development of RTT-based component systems. The
short-term goal is to interoperate between graphical notation of BRIDE and
textual syntax of ROCK in order to reuse code generation facilities of the
latter.
For those just interested in the outcome, please take a look at the bottom
of this email. For all the rest I have detailed some of the discovered
issues according to the tool they are related to, i.e. starting from RTT
meta-model, then ROCK and finally Xtext.
1. RTT meta-model
A number of minor issues with the RTT meta-model has been discovered and all of
them have been reported using bug tracking system. They are mostly related to
naming and cardinality of attributes, so I will not go into details here.
The most fundamental limitation of the RTT meta-model is related to modeling of
data-types for the generated code skeletons. Now it is only possible to use a
few of enumerated types (e.g., char, int, float, double and std::vector of
them). There is no such a limitation in RTT or ROCK and use of any C++ data
type (which is real-time safe) should be allowed. I think, that this is one of
the major issues, which need to be addressed. I have noticed some IDL-like
activity within the "bergamo" branch of the BRIDE repository, but I do not know
if/how it is going to be integrated with the RTT meta-model. Personally, I am
against inventing yet another IDL and prefer flexibility of ROCK, which allows
to use data-types coded directly in C++.
Another issue, is that RTT meta-model allows to design only "complete" systems.
For instance, cardinality of the outputPort.outputConnectionPolicy relationship
is set to 1, so all instances of the outputPort concept *must* be wired to some
input ports defined within *the same model*. Thus, it is not possible to create
a task context, which is not connected with any other entities. As a result, it
is not possible to use BRIDE for just a piece of an application. I think, that
this is a kind of design flaw, but it can be fixed rather easily.
Related to the above issue is mixing of "deployment" and "design" in the RTT
meta-model. These aspects are rather separated in ROCK (and I prefer this kind
of separation). For instance, the "name" attribute of a task context is not
specified until deployment section in ROCK. In RTT meta-model it needs to be
specified next to the task context itself.
There is also some minor clash between BRIDE and ROCK with respect to C++
namespaces in generated code skeletons. BRIDE generate task contexts as
'RTT::taskContext.namespace::taskContext.type' while ROCK as
'component.name::task.basename' (which I prefer). I see no point to make it
different and clearly there is a need for some kind of "convention" here.
In general, the RTT meta-model as defined in BRIDE is only a subset of the
implicit meta-model of ROCK. I have found a number of issues, which need to be
addressed. None of them seems to be really difficult to solve, but a kind of
agreement would need to be done between authors of BRIDE and ROCK. There is a
need to separate definition and deployment of task contexts in the meta-model,
but this is rather related to a more general issue of "composition".
2. ROCK (or "remarks on parsing internal DSLs")
I started with some ingenious definition of the ROCK component:
task_context "SimpleTask" do
output_port('out', 'double').
doc('documentation string').doc(doc('foo'))
operation('op1').returns('bool').returns('int')
end
It turns out, that this definition is perfectly acceptable for Orogen. However,
it is rather difficult to guess the outcome... - what will be the description
for the output port and what will be the return type for the operation? Of
course, one can easily fix these particular issues, but I think they are
illustrative examples of problems related to internal DSLs in general. Internal
DSLs need to be used with care, as there is (too) much freedom in using them.
I have assumed, that my goal is not to mimic the parser of Ruby, but to be as
close as possible to the *correct* use of ROCK. I started with a grammar
automatically generated by Xtext's wizard for the RTT meta-model. Then, I have
fine-tuned it step-by-step.
In general, the process of implementing subset of the ROCK syntax in Xtext is
not difficult. It definitely requires some time and effort (not to mention
about experience with the Xtext's internals...) to tune code formatting and
syntax highlighting. A kind of "template" for Ruby-like syntax would be more
than welcome. As far as I know this kind of feature/customization in not yet
available in Xtext.
3. Xtext
I have discovered two major issues related to use of Xtext for ROCK-like
syntaxes.
First issue is related to the 'port_driven' keyword in ROCK, which works
similar to 'private', 'public' and 'protected' keywords in C++. These keywords
modify attribute of an input port in ROCK and members of classes in C++
respectively. A single keyword modifies an attribute for *all* the following
entities and this kind of relationship is highly contextual. The problem is,
that it is not possible (or at least not easy) to express this kind of
relationship in BNF-like grammars. Thus, there is some post-processing of the
syntax tree required to set required attributes according to the context set up
by the keywords.
Second issue is related to representing bidirectional, opposite associations in
a textual notation. An example here is the ConnectionPolicy concept, which
links InputPort to OutputPort. The problem is, that user expects to express
these links only once (i.e., when specifying details of the connection), but
Xtext requires all the links to be reconstructed by the parser (i.e., it is
also required to reference a connection from the port's context).
I was not able to find a workaround for the above issue, but maybe some
advanced tuning of the meta-model can be used (e.g., some combination of the
'transient', 'volatile' and 'derived' properties).
In general, Xtext seems to be a good tool for the job, but there are still some
non-trivial issues to be solved. I am going to ask the Xtext community for some
hints, since I guess, that these issues are not only specific to this use-case.
*** Summary ***
Current state of development can be found using at the following location:
http://home.elka.pw.edu.pl/~ptrojane/orogen-syntax-editor.png
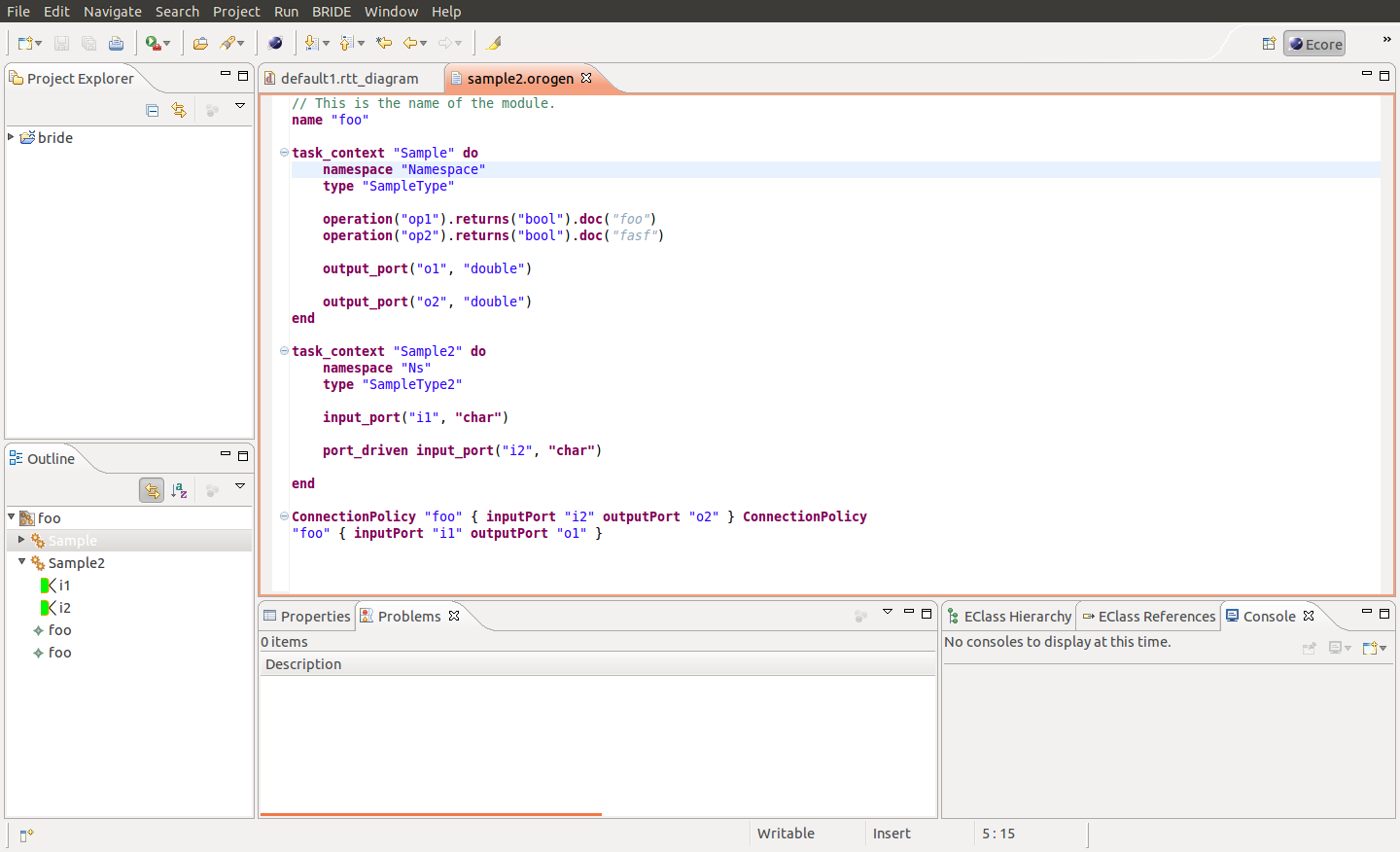{kind=link}
I did not wanted to bother you with screencast, but what you see is a result of
automatic formatting and custom syntax highlighting. I have added some custom
icons to the outline view. Code folding works out-of-the-box. TODO list include
code generation using templates both from BRIDE and ROCK (some general Eclipse
plugin-related stuff needs to be done for this).
As usual, comments are more than welcome!
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
Another thing:
How can/will you deal with extensions to the specification ? oroGen
supports having plugins, and it is a very widely used features for
Rock's stream aligner and transformer
http://rock-robotics.org/documentation/data_processing/stream_aligner_or...
http://rock-robotics.org/documentation/data_processing/transformer_oroge...
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On Tue, May 08, 2012 at 01:00:38PM +0200, Sylvain Joyeux wrote:
> How can/will you deal with extensions to the specification ? oroGen supports
> having plugins, and it is a very widely used features for Rock's stream
> aligner and transformer
>
> http://rock-robotics.org/documentation/data_processing/stream_aligner_or...
>
> http://rock-robotics.org/documentation/data_processing/transformer_oroge...
Oops, these URLs point to 404 error (I am not able to locate them with Google).
Anyway, Xtext support a concept of "grammar mixin" and I guess, that it can be
used to add support for "plugins" (at least at the EBNF-level). It may be
tricky to implement a proper "plugin" with Xtext, since the EBNF grammar is
only one piece of the story. There is also meta-model, code formatting, syntax
highlighting. Each of them has its own extension mechanism, but what you expect
is to package these extension as Eclipse plugins. I think, that it is not
trivial and in this sense the answer is NO - it is not possible to implement
this kind of extensibility.
I think, that this is an interesting remark on MDE-based tools in general.
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On 05/08/2012 05:14 PM, Piotr Trojanek wrote:
> On Tue, May 08, 2012 at 01:00:38PM +0200, Sylvain Joyeux wrote:
>> How can/will you deal with extensions to the specification ? oroGen supports
>> having plugins, and it is a very widely used features for Rock's stream
>> aligner and transformer
>>
>> http://rock-robotics.org/documentation/data_processing/stream_aligner_or...
>>
>> http://rock-robotics.org/documentation/data_processing/transformer_oroge...
>
> Oops, these URLs point to 404 error (I am not able to locate them with Google).
Was due to a change in the Rock website structure. Fixed it with some
mod_rewrite magic ... Should work now.
--
Sylvain Joyeux (Dr.Ing.)
Space & Security Robotics
!!! Achtung, neue Telefonnummer!!!
Standort Bremen:
DFKI GmbH
Robotics Innovation Center
Robert-Hooke-Straße 5
28359 Bremen, Germany
Phone: +49 (0)421 178-454136
Fax: +49 (0)421 218-454150
E-Mail: robotik [..] ...
Weitere Informationen: http://www.dfki.de/robotik
-----------------------------------------------------------------------
Deutsches Forschungszentrum fuer Kuenstliche Intelligenz GmbH
Firmensitz: Trippstadter Straße 122, D-67663 Kaiserslautern
Geschaeftsfuehrung: Prof. Dr. Dr. h.c. mult. Wolfgang Wahlster
(Vorsitzender) Dr. Walter Olthoff
Vorsitzender des Aufsichtsrats: Prof. Dr. h.c. Hans A. Aukes
Amtsgericht Kaiserslautern, HRB 2313
Sitz der Gesellschaft: Kaiserslautern (HRB 2313)
USt-Id.Nr.: DE 148646973
Steuernummer: 19/673/0060/3
-----------------------------------------------------------------------
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
Hi
Just to let you all know that I will reply to this list by tomorrow. I
am also using XText now and would like to think about this thread
more.
-H
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On 05/04/2012 07:03 PM, Piotr Trojanek wrote:
> 2. ROCK (or "remarks on parsing internal DSLs")
>
> I started with some ingenious definition of the ROCK component:
>
> task_context "SimpleTask" do
>
> output_port('out', 'double').
> doc('documentation string').doc(doc('foo'))
>
> operation('op1').returns('bool').returns('int')
> end
>
> It turns out, that this definition is perfectly acceptable for Orogen. However,
> it is rather difficult to guess the outcome... - what will be the description
> for the output port and what will be the return type for the operation?
+1: oroGen should generate an error for the double return. Moreover, I
am leaning towards removing the explicit doc tags and instead parsing
the comment above the declaration. Is that something that the tools you
are using can do ? (If not, I guess I'll keep the doc tag ...)
> Of
> course, one can easily fix these particular issues, but I think they are
> illustrative examples of problems related to internal DSLs in general. Internal
> DSLs need to be used with care, as there is (too) much freedom in using them.
Internal DSLs are as strict as you want them to be.
> I have assumed, that my goal is not to mimic the parser of Ruby, but to be as
> close as possible to the *correct* use of ROCK. I started with a grammar
> automatically generated by Xtext's wizard for the RTT meta-model. Then, I have
> fine-tuned it step-by-step.
Just a suggestion: why don't you do a convertion using a ruby library
that uses oroGen as its "parser" ? Another option: I don't know how
Xtext work, but you could in principle use jRuby and ripper to parse the
ruby code and then convert it to a suitable internal representation.
Directly accessing oroGen from jRuby is an unknown, however, as it needs
typelib and I don't know how well C/C++ extensions are supported from
within jruby (I know they are supported, but anyway ...)
> In general, the process of implementing subset of the ROCK syntax in Xtext is
> not difficult. It definitely requires some time and effort (not to mention
> about experience with the Xtext's internals...) to tune code formatting and
> syntax highlighting. A kind of "template" for Ruby-like syntax would be more
> than welcome.
What would you need in this template, exactly ?
> As far as I know this kind of feature/customization in not yet
> available in Xtext.
> A single keyword modifies an attribute for *all* the following
> entities
All the *preceding* entities in the case of port_driven
> *** Summary ***
>
> Current state of development can be found using at the following location:
> http://home.elka.pw.edu.pl/~ptrojane/orogen-syntax-editor.png
>
> I did not wanted to bother you with screencast, but what you see is a result of
> automatic formatting and custom syntax highlighting. I have added some custom
> icons to the outline view. Code folding works out-of-the-box. TODO list include
> code generation using templates both from BRIDE and ROCK (some general Eclipse
> plugin-related stuff needs to be done for this).
I am pretty impressed by what you managed to do far. Kudos !
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On Mon, May 07, 2012 at 09:41:13AM +0200, Sylvain Joyeux wrote:
> > It turns out, that this definition is perfectly acceptable for Orogen.
> > However, it is rather difficult to guess the outcome... - what will be the
> > description for the output port and what will be the return type for the
> > operation?
> +1: oroGen should generate an error for the double return. Moreover, I
> am leaning towards removing the explicit doc tags and instead parsing
> the comment above the declaration. Is that something that the tools you
> are using can do ? (If not, I guess I'll keep the doc tag ...)
I guess that there should be no problem with parsing implicit comments, since
they can be expressed using an underlying EBNF-like grammar. I think, that it
can be more difficult to parse these comments using Ruby and its reflection
features (but I am not Ruby expert).
> > DSLs need to be used with care, as there is (too) much freedom in using
> > them.
> Internal DSLs are as strict as you want them to be.
Definitely! One can say the same about hand-crafted parsers, but it is more
common to use tools like bison/flex to do the job.
I think, that key difference is in development process. Internal DSLs are much
more an art then a science (at least for me), while it is rather well known how
to deal with external ones. In particular, with internal DSL it is rather
difficult to _disallow_ a certain construct of the host language. Usually it
requires to rewrite AST analysis from scratch and so the main benefit of
internal DSLs vanishes. On the other hand, there are other pros of internal
DSLs, which are difficult to implement in external ones...
Please also take a look at the following example of oroGen input:
name "empty_component"
task_context "SimpleTas\nk" do end
In this case one gets the following error message:
In file included from /tmp/orogen_pending_loads20120421-7851-1h1i0h2-0:1:
/home/ptroja/foo/.orogen/empty_componentTaskStates.hpp:9: error: use of enum
'SimpleTas' without previous declaration
/home/ptroja/foo/.orogen/empty_componentTaskStates.hpp:10: error: function
definition does not declare parameters : cannot load one of the header files
/home/ptroja/foo/.orogen/empty_componentTaskStates.hpp: gccxml returned an
error while parsing /tmp/orogen_pending_loads20120421-7851-1h1i0h2-0
With a more complicated input/mistake an output message will be even more
cryptic. If you really want to tell the user about location of the problem,
then you have to implement a complete parser anyway :-(
> Just a suggestion: why don't you do a convertion using a ruby library that
> uses oroGen as its "parser" ? Another option: I don't know how Xtext work,
> but you could in principle use jRuby and ripper to parse the ruby code and
> then convert it to a suitable internal representation. Directly accessing
> oroGen from jRuby is an unknown, however, as it needs typelib and I don't
> know how well C/C++ extensions are supported from within jruby (I know they
> are supported, but anyway ...)
Unfortunately it will not work in this way. Xtext (and EMFtext also) relies on
a ANTLR-based parser generated from the EBNF-like definition of a particular
DSL. This parser is essential for features like code-completion and syntax
error detection -- it is not only for getting an internal representation.
> > In general, the process of implementing subset of the ROCK syntax in Xtext
> > is not difficult. It definitely requires some time and effort (not to
> > mention about experience with the Xtext's internals...) to tune code
> > formatting and syntax highlighting. A kind of "template" for Ruby-like
> > syntax would be more than welcome.
> What would you need in this template, exactly ?
Xtext comes with a kind of "template" for generating definition of the
following pieces from a single Ecore meta-model: (1) EBNF-like grammar, (2)
syntax highlighting and (3) code formatting. This "template" supports a kind of
default notation, which is pretty different from Ruby-like.
Unfortunately, it is not possible to substitute this "template" easily, as it
is hard-coded in Xtext. As a result, after each modification of the meta-model
one needs to retune all the above artifacts manually.
> I am pretty impressed by what you managed to do far. Kudos !
Thanks, but I the kudos should go to authors of Xtext, not to me... As for
reference - it required just about 350 lines of source code to develop this
kind of editor.
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
> I think, that key difference is in development process. Internal DSLs are much
> more an art then a science (at least for me), while it is rather well known how
> to deal with external ones.
And, being somebody that heavily used ANTLR, it is also pretty much an
art. Especially with error handling.
Now, internal DSLs (especially in Ruby) are a pretty well discussed and
documented technique. You can't really say, anymore, that you're on your
own when doing this.
> In particular, with internal DSL it is rather
> difficult to _disallow_ a certain construct of the host language. Usually it
> requires to rewrite AST analysis from scratch and so the main benefit of
> internal DSLs vanishes. On the other hand, there are other pros of internal
> DSLs, which are difficult to implement in external ones...
Yes. You have to deal with the host language's idioms. And when using
other parsers, you have to deal with the representation's idioms and the
limitations of whatever parsing technique you are using. Not so different.
[snip]
> With a more complicated input/mistake an output message will be even more
> cryptic. If you really want to tell the user about location of the problem,
> then you have to implement a complete parser anyway :-(
No you don't. Finding were each of the DSL construct is called from can
be done very easily (use Kernel#caller). That's also how people read
comment documentation: use either caller or Method#source_location to
find the place of the method definition and parse the comments above
that line.
>> I am pretty impressed by what you managed to do far. Kudos !
>
> Thanks, but I the kudos should go to authors of Xtext, not to me... As for
> reference - it required just about 350 lines of source code to develop this
> kind of editor.
Well, as always, I find that what takes most code are the corner-cases
(which are numerous so far), so I would not say a "wow" quite yet on the
350 lines.
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On Tue, May 08, 2012 at 01:07:35PM +0200, Sylvain Joyeux wrote:
> And, being somebody that heavily used ANTLR, it is also pretty much an art.
> Especially with error handling.
Fortunately ANTRL is completely hidden in case of Xtext :-)
> No you don't. Finding were each of the DSL construct is called from can be
> done very easily (use Kernel#caller). That's also how people read comment
> documentation: use either caller or Method#source_location to find the place
> of the method definition and parse the comments above that line.
Looks promising! I was not aware if these features. I have read some tutorials
about writing DSLs in Ruby, but have not seen these calls in action yet.
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On 05/08/2012 11:41 AM, Piotr Trojanek wrote:
> Please also take a look at the following example of oroGen input:
>
> name "empty_component"
>
> task_context "SimpleTas\nk" do end
>
> In this case one gets the following error message:
>
> In file included from /tmp/orogen_pending_loads20120421-7851-1h1i0h2-0:1:
> /home/ptroja/foo/.orogen/empty_componentTaskStates.hpp:9: error: use of enum
> 'SimpleTas' without previous declaration
> /home/ptroja/foo/.orogen/empty_componentTaskStates.hpp:10: error: function
> definition does not declare parameters : cannot load one of the header files
> /home/ptroja/foo/.orogen/empty_componentTaskStates.hpp: gccxml returned an
> error while parsing /tmp/orogen_pending_loads20120421-7851-1h1i0h2-0
>
> With a more complicated input/mistake an output message will be even more
> cryptic. If you really want to tell the user about location of the problem,
> then you have to implement a complete parser anyway :-(
This is called an input sanitization problem, which is something you
have to do anyways (and I am a bit concerned that this particular issue
was not caught, as I thought it was sanitized). Moreover, you only have
to deal with that, instead of having to deal with parsing errors.
Generating proper parser errors *is* very tricky.
Gluing ROCK with BRIDE (or remarks about pre-alpha ROCK-like tex
On 05/04/2012 07:03 PM, Piotr Trojanek wrote:
> 2. ROCK (or "remarks on parsing internal DSLs")
>
> I started with some ingenious definition of the ROCK component:
>
> task_context "SimpleTask" do
>
> output_port('out', 'double').
> doc('documentation string').doc(doc('foo'))
>
> operation('op1').returns('bool').returns('int')
> end
>
> It turns out, that this definition is perfectly acceptable for Orogen. However,
> it is rather difficult to guess the outcome... - what will be the description
> for the output port and what will be the return type for the operation?
+1: oroGen should generate an error for the double return. Moreover, I
am leaning towards removing the explicit doc tags and instead parsing
the comment above the declaration. Is that something that the tools you
are using can do ? (If not, I guess I'll keep the doc tag ...)
> Of
> course, one can easily fix these particular issues, but I think they are
> illustrative examples of problems related to internal DSLs in general. Internal
> DSLs need to be used with care, as there is (too) much freedom in using them.
Internal DSLs are as strict as you want them to be.
> I have assumed, that my goal is not to mimic the parser of Ruby, but to be as
> close as possible to the *correct* use of ROCK. I started with a grammar
> automatically generated by Xtext's wizard for the RTT meta-model. Then, I have
> fine-tuned it step-by-step.
Just a suggestion: why don't you do a convertion using a ruby library
that uses oroGen as its "parser" ? Another option: I don't know how
Xtext work, but you could in principle use jRuby and ripper to parse the
ruby code and then convert it to a suitable internal representation.
Directly accessing oroGen from jRuby is an unknown, however, as it needs
typelib and I don't know how well C/C++ extensions are supported from
within jruby (I know they are supported, but anyway ...)
> In general, the process of implementing subset of the ROCK syntax in Xtext is
> not difficult. It definitely requires some time and effort (not to mention
> about experience with the Xtext's internals...) to tune code formatting and
> syntax highlighting. A kind of "template" for Ruby-like syntax would be more
> than welcome.
What would you need in this template, exactly ?
> As far as I know this kind of feature/customization in not yet
> available in Xtext.
> A single keyword modifies an attribute for *all* the following
> entities
All the *preceding* entities in the case of port_driven
> *** Summary ***
>
> Current state of development can be found using at the following location:
> http://home.elka.pw.edu.pl/~ptrojane/orogen-syntax-editor.png
>
> I did not wanted to bother you with screencast, but what you see is a result of
> automatic formatting and custom syntax highlighting. I have added some custom
> icons to the outline view. Code folding works out-of-the-box. TODO list include
> code generation using templates both from BRIDE and ROCK (some general Eclipse
> plugin-related stuff needs to be done for this).
I am pretty impressed by what you managed to do far. Kudos !